
Výstup profileru
Nejprve si zopakujme, že podoba výstupu není pevně dána a můžete ji měnit. Tedy tato kapitola nemá být uživatelský manuál mikroaplikaci _profiler, ale především soupis informací, se kterými profiler operuje a také vysvětlení smyslu těchto informací. Tak hurá do toho.
Doba běhu
Naprosto základní informace a indikace zda je s aplikací vše v pořádku. Není třeba připomínat, že provedení požadavku musí zabrat minimum času. To má vliv na pocit uživatele z aplikace, ale také na zátěž serveru (a tedy pomyslné přežití aplikace pod zátěží) a například takový Google pomalé weby také moc rád nemá.
Tato informace je tedy to první co vidíte ve stavovém proužku.
Pozor! Tento časový údaj zahrnuje pouze rozmezí mezi startem Profileru a ukončením.
Nezahrnuje (a ani z podstaty věci nemůže zahrnovat):
- Jakékoliv latence síťového spojení, samotného webserveru a podobně.
- Režii PHP pro parsování a spouštění skriptů
- Nezahrnuje cokoliv v rámci aplikace co bylo vykonáno před aktivací profileru. Proto se Profiler inicializuje co nejdříve. Před ním se provádí pouze základní nastavení a to by mělo zabrat minimum času.
Spotřeba paměti
S tím se to má vlastně úplně stejně jako s dobou běhu. Tedy viz předchozí text.
Stav keše
Toto je velice důležité! Indikace zda je / není zapnutá keš (Autoloader a MVC) je rozhodující. V praxi to dělám tak, že ladím aplikaci jak s vypnoutou keší (to nejprve) tak, aby její výkon byl dostatečný i bez kešge, tak po té i se zapnutou keší - tedy v podobě a stavu v jakém bude běžet na produkčním prostředí v praxi a provozu.
Proč je to důležité a proč testovat v obou režimech?
- Aplikace musí být slušně rychlá i bez keše. Co je platné že s keší je request odbaven za 0,1s, když se studenou keš generuje třeba i stovky SQL dotazů a i na vašem nezatíženém localhostu se request provádí třeba 1,2s. (trochu extrémní případ, ale může se to stát). To je nepřijatelný stav a pro aplikaci to znamená do budoucna problémy.
- Aplikace musí dobře a správně fungovat i s keší. Může se stát, že se zapnutou keší něco začně chovat trochu jinak než bez keše. To je jeden důvod. A druhý důvod je ten, že keš nemusí zafungovat jak předpokládáte a aplikace nebude po jejím zapnutí tam výkonná jak jste očekávali.
Tedy je nutné vyzkoušet a ověřit vše. Proto je údaj o stavu cache jedna z klíčových informací.
Počet SQL dotazů
Tvrdím, že v našem oboru platí, že SQL je skvělý sluha, ale velice krutý pán. Převážná část problémů s výkonností online aplikací se kterými jsem se za svou praxi setkal měla příčinu právě v práci s relační databází - tedy SQL. Klasické problémy:
- Velké množství SQL dotazů ...
- Neoptimalizované dotazy, nezaindexované tabulky
- Celkově nejasná koncepce práce s relační databází ... (např. zbytečné opakované volání dotazů a podobně).
Bohužel se dá říct, že řada vývojářů (naštěstí zdaleka ne všichni) s databází pracuje a vůbec je nenapadne uvažovat nad tím, že každý takový dotaz se přes TCP/IP pošle serveru pomocí jeho protokolu, tam se parsuje, pak zpracovává/provádí a server "loví" data z tabulek, čte z disku, dává to v paměti (nedej bože opět na disku) do kupy a pak to stejnou cestou posílá zpět. To je vlastně šílené množství práce a použitých prostředků (paměti, CPU, síťového spojení, celkového času)
Proto jsem se naučil, že čím méně SQL tím méně problémů. Ne, relační databáze nepovažuji za nic zlého. Naopak. Je to skvělé! Ale musí se na to s rozmyslem. Je to jako se vším na tomto světě :-) Relační databáze prostě nemá být středobodem a hlavním "srdcem a mozkem" online aplikace. Vím, že se mnou budou mnozí třeba i nesouhlasit. Já si také kdysi dávno myslel něco jiného. Ale praxe mě prostě dovedla k tomuto poznání a přesvědčení.
A z toho důvodu je počet SQL dotazů jeden ze základních indikátorů (pochopitelně ještě záleží i na tom jaké ty dotazy jsou - kvalita je důležitá jako kvantita). Ale dá se říct, že snaha je poslat uživateli výstup ideálně s počtem SQL dotazů 0 (pokud to jde - zejména při použití různých cache a předgenerovaných výstupů)
Stav balíčkovačů CSS a JS
Indikuje zda Jet dělá z požadovaných CSS a JS souborů balčky (shlukuje do jednoho souboru). To nemá vliv na zpracování konkrétního požadvku aplikací, ale má to vliv na celkovou rychlost načtení aplikace v prohlížeči uživatele. Tedy dobré vědět :-)
Běhové bloky
V detailu informací o daném běhu je aplikace rozdělená do bloků. Tyto bloky jsou do sebe zanořené - jedná o stromovou strukturu, kdy rodičovský blok je souhrnem běhových informacích všech svých potomků. Lze tak podrobně pátrat kde je problém.
V praxi to vypadá takto:
Bloky si můžete (a máte) sami definovat.
Ale pokud používáte plný MVC subsystém, tak to pro vás Jet udělá do velký míry sám, ale samozřejmě zůstává zachována možnost tvořit další bloky ručně.
Samořejmě pokud vyvíjíte aplikaci bez Jet MVC, tak je to na vás a vašem uvážení zda a jak si bloky vytvoříte.
Informace o běhovém bloku
Doba běhu
Toto jsme si již popisovali v kontextu celkových informací co Profiler zobrazuje. Jediný rozdíl je ten, že zde je to v kontextu začátku a konce běhového bloku.
Spotřeba paměti
V rámci bloku je zobrazeno o kolik se spotřeba paměti v rámci bloku změnila. Cílem je identifikovat místo kde došlo k největšímu nárůstu spotřeby paměti.
Zprávy - messages
Pro snadnější a přehlednější ladění si můžete k bloku přidat různé ladící informace. Někdy to Jet už dělá za vás a některé užitečné informace doplní sám, ale hlavně je to ve vaší moci.
Všimněte si, že krom zprávy vidíte i místo ze kterého byla zpráva poslána.
Provedené SQL dotazy
Krom celkového přehledu o všech provedených SQL dotazech (viz dále) máte možnost vidět právě ty dotazy, které byly provedeny v daném bloku. Informace jsou stjené jako v celkovém přehledu dotazů (viz dále), pouze je to vztaženo ke konkrétnímu bloku.
Informace o začátku a konci bloku
Pro lepší přehlednost je uváděna informace kde blok začíná a kde končí (v jakém skriptu, na jakém řádku). Součástí této informace je i backtrace.
Anonymní bloky
Pokud místo názvu bloku vidíte znak "?", pak se jedná o anonymní blok. Co to je? Dejme tomu, že na dané úrovni je jeden blok ukončen, ale další ještě nezačal, tak systém ví, že je momentálně takto v pomyslném vzduchoprázdnu a inicializuje anonymní blok a do něj sbírá informace.
Anonymní blok je úplně stejný jako vámi (nebo Jetem) definovaný pojmenovaný blok, pouze není znám název a je vytvořen i uzavřen zcela automaticky . Jakmile je označen začátek pojmenovaného bloku, tak anonymní blok automaticky končí.
SQL dotazy - celkový přehled
O důležitosti sledování situace kolem SQL dotazů jsem již psal. Teď si ukážeme co v rámci této problematiky Profiler umožňuje. Koukněme se nejprve na příklad výstupu:
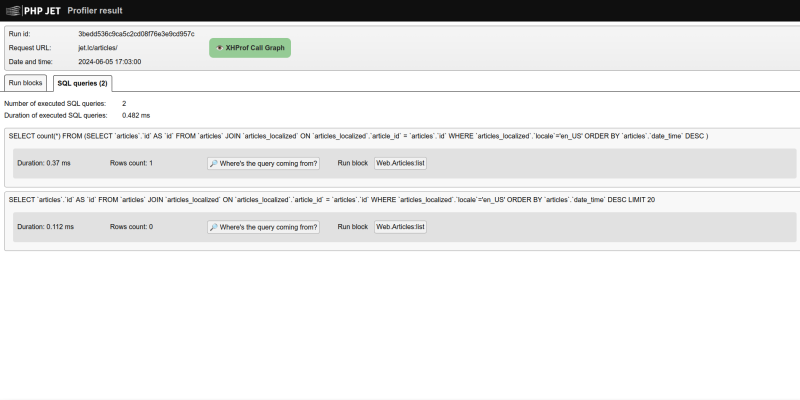
- Hned první informace je v jakém bloku byl dotaz proveden. Stejně tak jako máte u daného bloku výčet provedených dotazů (zcela totožné informace jako jsou tyto), tak se celkový přehled dotazů odkazuje na bloky.
- Následuje SQL dotaz samotný.
- Nesmí chybět informace o tom jak dlouho trvalo provedení dotazu.
- Počet řádek výsledku SELET (nebo ovlivněných řádků - např. UPDATE) je tak důležitá informace, která může být důrazným varováním před prací s příliš velkým množstvím dat.
- A nesmí chybět backtrace místa, kde byl dotaz proveden.
Samozřejmě na úplném konci nesmí scházet celkový souhrn: kolik dotazů bylo provedeno a jak dlouho jejich provedení celkově zabralo.
Přeji vám, ať máte čísla a běhové informace vždy co nejpříznivější ;-)